

{kind=link}
Designing chips and shepherding them through the foundry and package and assembly is a complex and difficult process, and not having these skills at a national level has profound implications for the competitiveness of those nations.
In many ways, Europe behaves more like a nation than not, and this is certainly true of supercomputing, which has been a collaborative affair for the past several decades. In the late 2010s, just as the wave of accelerated computing in HPC was building toward its current crescendo in the AI space, Europe grew tired of being dependent on the compute engines from American and Japanese vendors for its supercomputers and formed the European Processor Initiative to create indigenous European compute engines and the EuroHPC Joint Venture to fund pre-exascale and exascale systems installed throughout Europe. Three exascale systems have been budgeted thus far.
There have been some potholes and mud delays on the EPI processor and accelerator roadmaps, but Europe remains committed to the idea of being as indigenous as possible under the circumstances when it comes to the compute engines that will be used in its exascale systems.
This is on our minds as we learn a little bit more about Europe’s second exascale system, which is going to be called “Alice Recoque” and which will be hosted in France, at the same time that we are chewing on the delay by SiPearl of its first generation “Rhea1” Arm-based processor being designed as the host processor for the EuroHPC consortium that is fomenting the designs of CPUs and accelerators under the EPI effort.
Delays in processor delivery are the rule in the chip business, not the exception, even though it may not look at it from the outside. Chip designer/sellers – we hesitate to use the noun “makers” because they don’t usually make the chips with the exception of Intel these days – build in buffers and that is how they stick to a fairly regular roadmap. The SiPearl chip startup that is designing the Rhea family of CPUs, which are intended to be used as host processors for Europe’s exascale supercomputers as well as for computational engines for the CPU-only workloads that are common in the HPC space, is learning all of these skills in real-time. And it has blown through a bunch of its buffers as it designs its first chip. This is unfortunate for the EPI effort and for Europe’s exascale aspirations, but Europe has contingency plans as it tries to cultivate indigenous chippery.
You have to play the very long game here, including investing in the foundries and packaging firms so they will build advanced factories in Europe, if you want to be able to stand on your own two feet, as Europe most certainly does.
SiPearl is a startup located in France outside of Paris, and its Rhea1 CPU is at the heart of the “Jupiter” exascale supercomputer that is going to be installed this year at the Forschungszentrum Jülich in Germany. The EuroHPC JV has not given out a lot of details on the final Jupiter configuration, but we do know that the so-called “GPU Booster” part of the Jupiter system will probably be based on “Grace” CG100 Arm server chips and “Hopper” H100 GPU accelerator superchips from Nvidia. The reason we say probably is because we think there is a reasonably good chance that when the GPU Booster module of Jupiter is fired up sometime later this year, it could be based on “Blackwell” B100 GPUs from Nvidia, which offer 2.3X more FP64 performance as the H100s at an incremental cost anticipated to be around 1.6X.
We got a peek at what could account for most of the computational power of the Jupiter system on the June rankings of the Top 500 supercomputers, when FZJ was showing off a prototype system called “Jedi” comprised of Grace-Hopper superchips linked by a quad-rail 200 Gb/sec NDR InfiniBand network also from Nvidia. Jedi is short for Jupiter Exascale Development Instrument, and it has 24 Grace-Hopper superchips, which delivers a peak 5.1 petaflops of FP64 performance and 4.5 petaflops on the High Performance LINPACK benchmark. Importantly, at 67.3 kilowatts of power consumption, this rack of Grace-Hopper systems delivers 72.7 gigaflops per watt, which makes it the most energy efficient machine tested on various HPC benchmarks. Blackwell GPUs would presumably push that energy efficiency even higher for the GPU Booster.
We presume that to save face and to put Rhea1 through a real stress test, EuroHPC and EPI both want the Universal Cluster (also known as the Cluster Module) for Jupiter to still be based on the Rhea1 processor, even though the delivery of this CPU has now been pushed out to 2025 and even though it is based on the Neoverse “Zeus” V1 cores from Arm.
But no matter what, because EPI did not deliver a RISC-V accelerator for Jupiter that could displace Nvidia GPUs – it is still going to try to do that, we think – there are going to be plenty of Arm cores available to run applications that only speak CPU because of the switch to Nvidia superchips for the GPU booster.
The vast majority of compute capacity for Jupiter will be in the GPU accelerated nodes. And by using the Nvidia superchip in those GPU Booster nodes, there will be lots of Grace processors available – one for every Hopper or Blackwell GPU, to be precise. To break 1 exaflops of performance comfortably on the LINPACK test, it might take 32,000 nodes with H100s and maybe 16,000 nodes with B100s, and so that would be 32,000 or 16,000 Grace CPUs with 72 cores each, for a total of either 2.3 million or 1.15 million cores. We think the latter is desirable in terms of GPU performance and energy efficiency, but it is hard to say if EuroHPC can get Nvidia to let go of Blackwell GPUs for the Jupiter system. And if all Nvidia has is H100s in the Jupiter timeframe, then FZJ will get twice as many Grace cores to play with as it awaits the Rhea1 delivery and the Universal Cluster based on it.
For comparison, the “Juwels” system at FZJ is based on Intel “Skylake” Xeon 8168 processors with 114,840 cores with 9.9 petaflops of peak aggregate FP64 performance. The more recent “Juwels Booster” system installed in 2020 has 449,280 cores of AMD’s Epyc 7402 processors and is rated at just under 71 petaflops peak. Our based guess, derived from the performance of the Grace-Grace superchips used in the Isambard 3 system installed at the University of Bristol, is that the 32,000 Grace CPUs in the GPU Booster of Jupiter would all by themselves deliver around 225 petaflops of performance at FP64. That is 2.8X times the all-CPU performance of the Juwels and Juwels Booster all-CPU systems installed currently at FZJ.
Anything Rhea1 adds to this is incremental and good, and software that was created for Rhea1 can run on Grace and vice versa because they both adhere to Arm standards.
As we previously reported back in April 2023, Rhea1 was expected to have 72 cores based on the “Zeus” V1 cores from Arm and to be available this year. After the latest delay, SiPearl is now saying that it will deliver Rhea1 with a maximum of 80 cores sometime in 2025. That is an 11 percent increase in throughput at a constant clock speed, which helps assuage the issues surrounding the delay a bit.
We think the original plan was 72 cores using the 7 nanometer processes from Taiwan Semiconductor Manufacturing Corp, and that somewhere along the way SiPearl shifted to TSMC’s N6 modification of the 7 nanometer process and was able to add eight more active cores to the design. (84 cores would be easier to add because the original design appeared to be six columns of twelve cores each, and four cores could be lost to yield.)
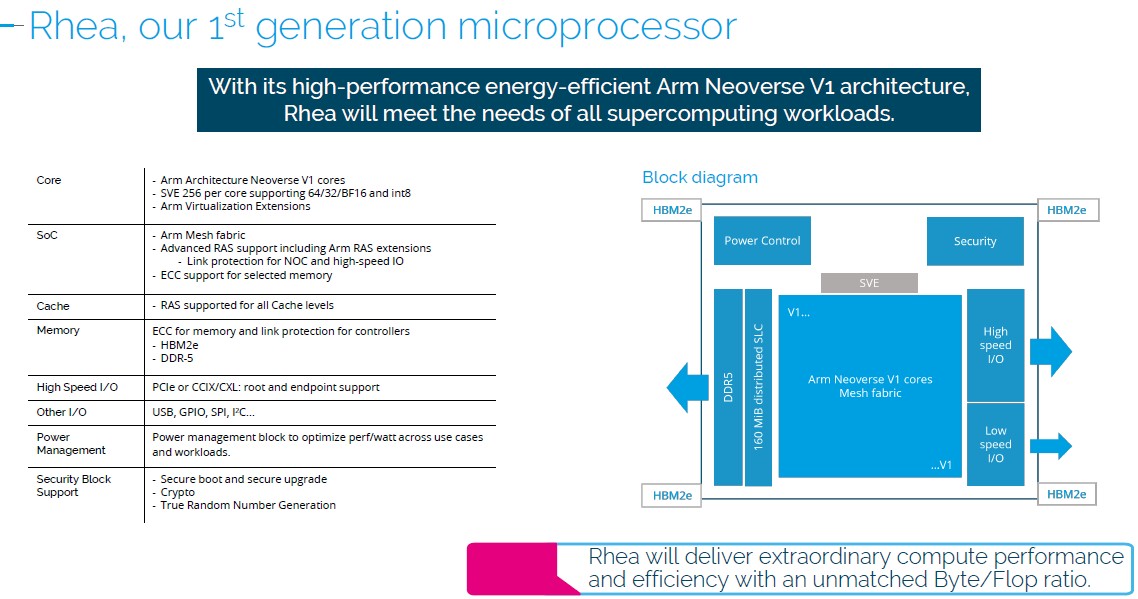
The Rhea1 chip has a mix of both DDR5 main memory and HBM2e stacked memory, and for all we know, it is the mixed memory subsystem that is causing the delays with this processor. The specs we saw from 2020 show it with four DDR5 memory controllers, but now we see that it has four HBM2e memory stacks as well, which are coming from Samsung. The chip is also expected to have 104 lanes of PCI-Express 5.0 across its I/O controllers.
One more thing to consider: It is important that Nvidia used the “Demeter” V2 cores in the Grace CPU. Those V2 cores are also being used by Amazon Web Services in its impending “Graviton4” homegrown processor. The V1 cores in the Zeus cores used in Rhea1 have a pair of 256-bit SVE2 vector engines, but the V2 cores have a quad of 128-bit vectors that are more efficient at certain kinds of processing.
Anyway, to a certain way of thinking, then, 32,000 Grace-Hopper superchips to reach an exaflops of peak FP64 performance on LINPACK is better than 16,000 Grace-Blackwells when it comes to FZJ because you get twice as many CPUs that way.
Which brings us all the way to the Alice Recoque system that will be installed at GENCI, operated by CEA (the French equivalent of the US Department of Energy), and paid for by the French and Dutch governments alongside of the EuroHPC JV collective.
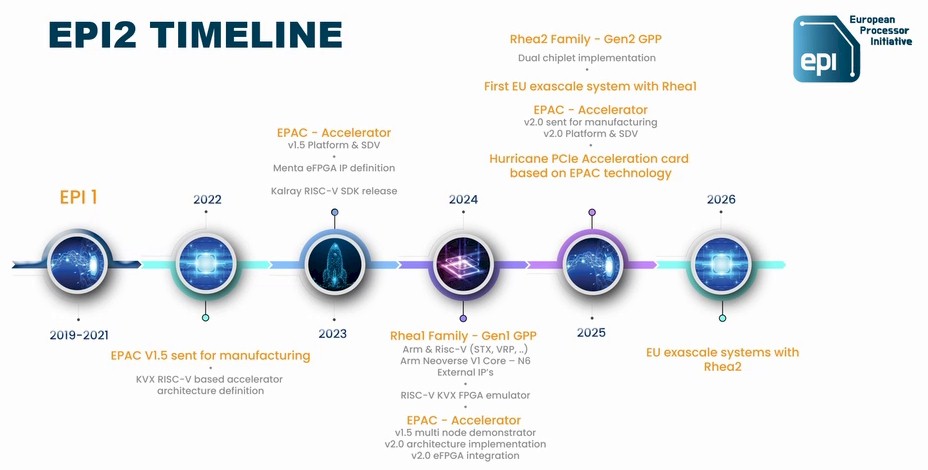
The Rhea2 chip is expected to be comprised of two chiplets and according to the roadmap above, from earlier this year, it was expected to be finished in 2025 and for exascale systems (plural) using Rhea2 to be installed in Europe in 2026. Our guess is two chiplets with at least 64 cores each, which would be 1.6X more performance. Rhea2 could try to push all the way to 192 cores, with 96 cores per chiplet. This would be 2.4X the number of cores as the Rhea1, but we think the clock speeds would have to come down a bit, so it might only be 2X the performance when all is said and done.
If SiPearl wants to stay out of trouble with the Rhea2 chip, we strongly advise for the company to work with Arm and use the “Poseidon” V3 core and its “Voyager” Compute Sub System (CSS) V3 package. The that will help all chip designers to streamline the process and speed up development. (We covered the latest Arm server chip roadmap back in February of this year.) There is no time to try to do everything from scratch and meet that 2026 deadline for Rhea2 and the Alice Recoque system going into GENCI and run by CEA.
Arm launched the CSS effort back in August 2023, and showed how adopting the CSS stack, which includes cores, mesh interconnect, I/O controllers all ready to go, could save 80 engineer-years of effort. With only 190 employees and only two years to get Rhea2 out the door, which is 380 engineer-years, SiPearl would seem to be an ideal candidate for the Voyager CSS V3 package.
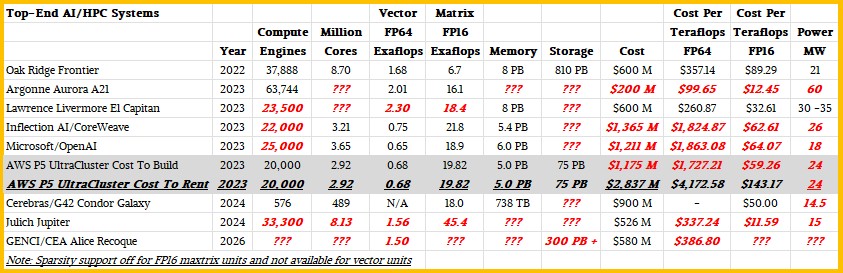
In the table above, the Jupiter machine has 32,000 Grace-Hopper nodes. In the other machines, the CPUs are largely ignored when there are GPUs present, but we do not think this will be the case with Jupiter for reasons we stated above. There is a rumor that the Rhea1 cluster will only have 1,300 nodes. This is not very much performance.
We think that the EuroHPC JV really wants to have Rhea2 in all of the nodes of the Alice Recoque system and also wants the “Hurricane” EPAC accelerated based on the RISC-V architecture in the system. We think that there will be a high number of these EPAC coprocessors attached to each Rhea2 CPU, and we also think they will be configured in a four to one ratio between CPUs and accelerators. We have no idea what the performance of the Hurricane devices will be or how efficient it will be, so we cannot reckon how many it will take to break the 1 exaflops barrier on LINPACK.
And if this all goes to heck, then the EuroHPC JV can fund a system based on Nvidia motors using future “Vera” Arm server CPUs and “Rubin” GPU accelerators and call it a day.
We also think it would be inconceivable for Alice Recoque to not be built by Eviden, the supercomputing spinout of French system maker and IT services supplier Atos.
The Alice Recoque system has a budget of €542 million ($580.2 million), with €271 million ($291.1 million) coming from the EuroHPC JV, €263 million ($281.5 million) coming from the French government and €8 million ($8.6 million) coming from the Dutch government.
By the way, the namesake of the second exascale system in Europe, Alice Arnaud Recoque, was born in in Algeria in 1929 and got her graduate degree in engineering from ESPCI Paris, akin to the MIT of France, in 1954. She worked at Société d’Electronique et d’Automatisme (SAE) after graduating, helping design many generations of minicomputers, specifically the Mitra line that was created to compete against Digital Equipment Corp’s PDP and VAX lines. In 1985, she moved to Bull Group and worked on parallel supercomputers and artificial intelligence, and was also a computer science professor at a number of prominent French universities.